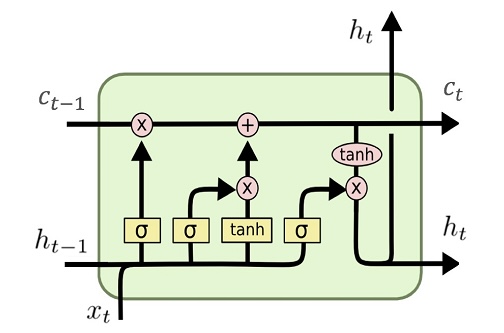
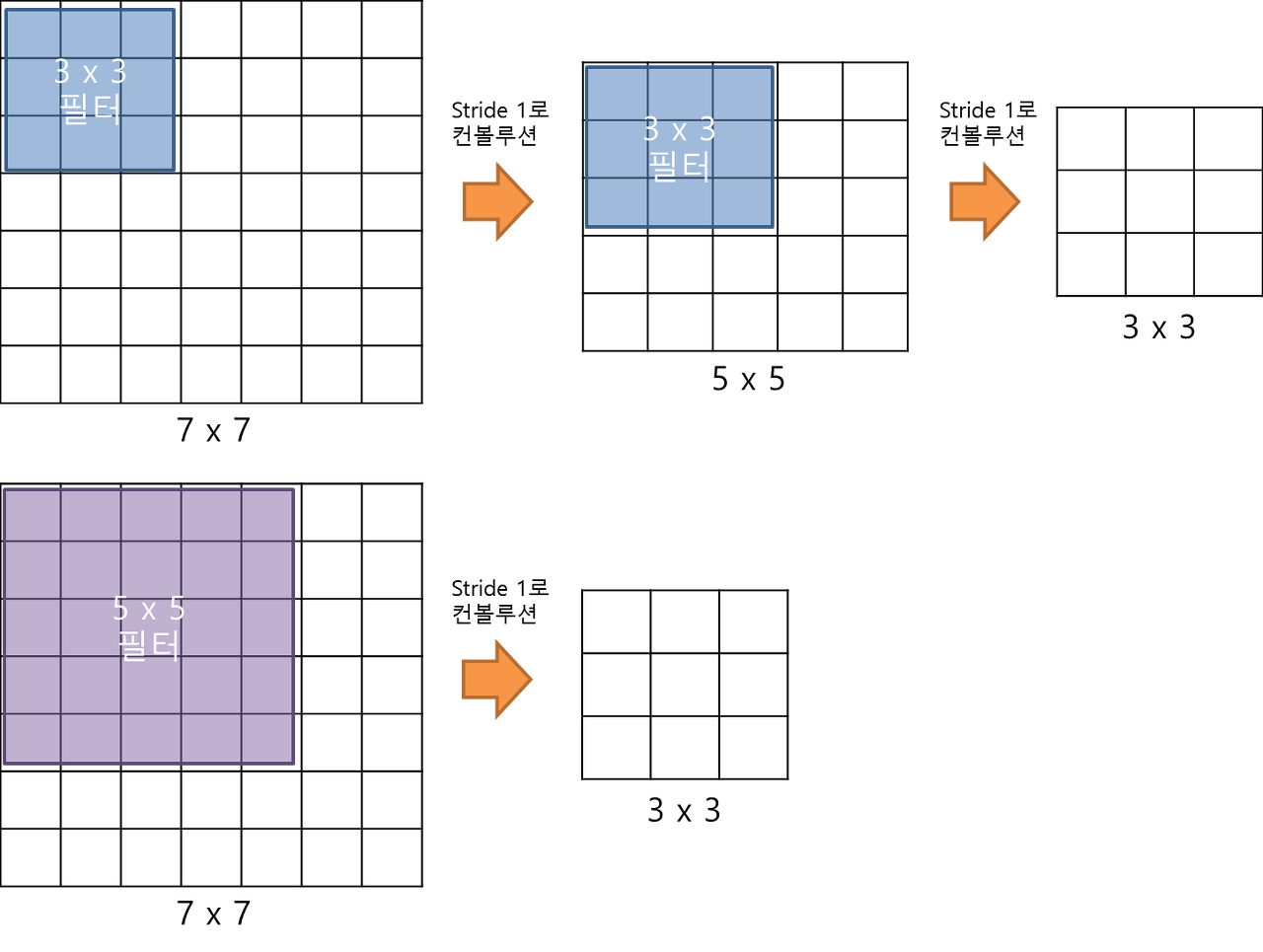
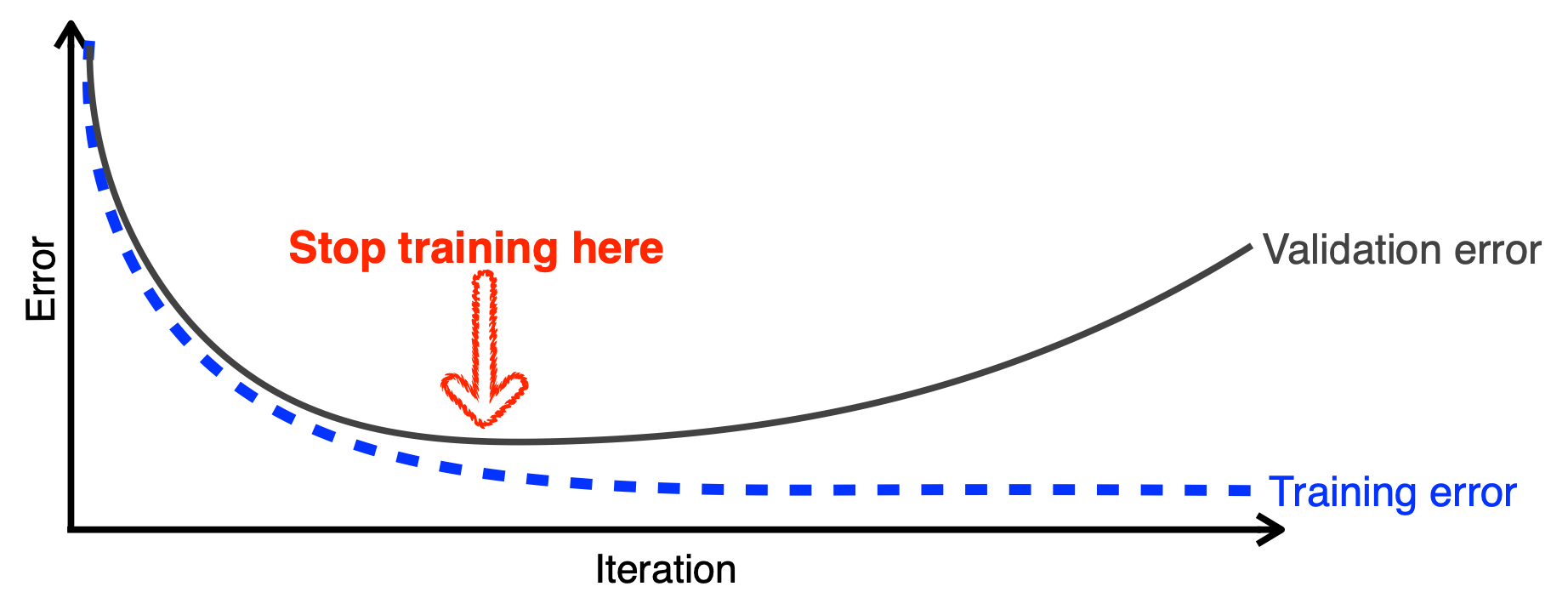
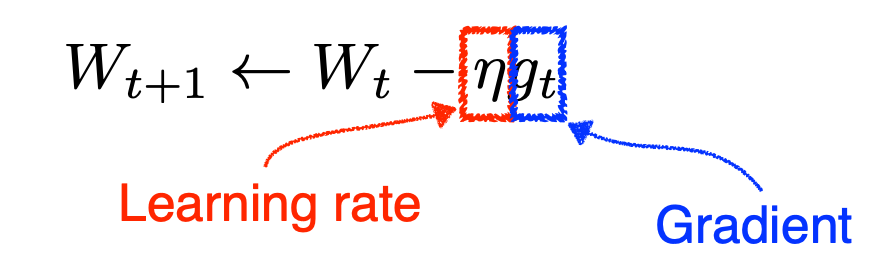
HuggingFace Trainer는 PyTorch와 같은 딥러닝 프레임워크에서 모델을 학습하기 위한 편리한 인터페이스를 제공하는 파이썬 라이브러리이다. Trainer 클래스와 TrainingArguments 클래스는 Trainer를 사용하여 모델을 학습시키기 위한 설정과 제어를 담당하는 중요한 클래스들이다. 이 두 클래스를 통해 모델 학습의 다양한 설정을 조정하고, 학습 과정을 관리할 수 있다. Trainer 클래스 Trainer 클래스는 모델의 학습을 관리하고 제어하는 클래스로, transformers 라이브러리에서 제공되는 핵심 클래스 중 하나이다. Trainer 클래스를 사용하면 모델 학습에 필요한 다양한 기능들을 활용할 수 있다. 주요 속성 model: 학습할 모델 객체. PyTorch와 같은 ..