논문이 다루는 Task
본 논문에서는 LSTM을 활용해 높은 정확도로 입력 sequence가 주어졌을 때, 그에 상응하는 출력 sequence를 생성해내는 아키텍쳐를 제안하고, 이를 기계 번역 task에 사용한다.
기존 연구 한계
DNN (Deep Neural Network)
DNN은 입력 벡터와 출력 벡터의 차원이 고정적이다. 따라서, 출력 벡터의 차원(출력 sequence의 길이)를 사전에 알기 힘든 Seq2Seq task에는 적합하지 않다.
RNN (Recurrent Neural Network)
일반적으로 sequence 학습을 위해서는 RNN을 활용한 encoder와 decoder 구조를 사용한다. 그러나 이 방법은 long-term dependency 문제로 인해 이전의 정보들이 뒤로 갈수록 보존이 되지 못한다는 한계가 존재했다.

RNN을 활용해 sequence와 sequence를 매핑할 수 있지만, 입력 sequence와 출력 sequence의 길이가 다르거나 두 sequence 간에 관계가 단조롭지 않다면(예를 들어, 어순이 다른 경우) 적용하기 쉽지 않다.
제안 방법론
기존 연구의 한계를 극복하고자 본 연구에서는 LSTM을 활용한 encoder와 decoder 구조를 제안한다.
입력 sequence를 encoder에 넣어 고정된 크기의 벡터 v를 추출한다. 이 벡터는 입력 sequence의 전체적인 내용을 담고 있는 벡터이다. 이렇게 추출된 벡터를 decoder의 초기 hidden state로 넣어주어 출력 sequence를 얻어내는 것이다.
고정된 크기의 벡터 v는 encoder에서 LSTM의 마지막 hidden state이며, encoder와 decoder는 서로 다른 파라미터를 갖는다.
성능 향상을 위해 4개의 layer로 이루어진 LSTM을 사용하였다.
본 연구에서 출력 문장의 품질을 높이기 위해 독특한 방식을 사용했는데 입력 문장의 순서를 거꾸로 뒤집어 encoder에 전달하는 것이었다.
입력 문장의 순서를 거꾸로 뒤집게 되면 첫 단어가 가장 마지막에 위치하게 된다. 이렇게 되면 decoder의 초기 hidden state로 전달되는 문맥 벡터 v에 첫 단어에 대한 정보가 높은 비중으로 담기게 된다. 따라서 decoder의 입장에서는 출력 문장의 첫 단어를 만들 때 문맥 벡터 v에서 입력 문장의 초반 단어들의 정보를 많이 얻을 수 있어 첫 단어를 생성해내기 수월해진다. 결과적으로 첫 단어의 정확도가 높아지면, 이전 데이터가 이후 데이터에 영향을 미치는 sequence task의 특성상 더 좋은 품질의 출력 문장을 얻어낼 수 있게 되는 것이다.
decoder에서는 가장 가능성이 높은 출력 문장을 찾기 위해 left-to-right beam search decoder를 사용했다.
beam search란 각 step마다 각각의 후보 sequence마다 유효한 단어를 이어 붙인 다음, 가장 확률이 높은 k개(여기서 k는 사용자가 지정하는 hyper parameter이다.)의 후보 sequence 외에 나머지를 제거한 뒤, 다음 step을 진행한다.
이 과정을 <EOS> 토큰이 생성될 때까지 진행하여 출력 문장을 생성한다.
Contribution
- 딥러닝을 활용해 높은 정확도로 기계 번역 task를 수행할 수 있는 아키텍쳐를 제안했다.
- 2017년 Transformer가 등장하기 전까지 state-of-the-art로 사용되었다.
실험 및 결과
Dataset
WMT’14 English to French dataset을 사용해 실험을 진행하였다. 해당 데이터 셋은 1200만개의 문장으로 이루어져 있으며 3억 4800만개의 프랑스어 단어와 3억 4백만개의 영어 단어를 포함한다.
각 단어를 one-hot encoding 벡터로 표현해야 하므로 가장 많이 사용되는 16만개의 영단어 어휘와 8만개의 프랑스어 어휘를 학습에 사용하였고, 그 외 단어들은 “UNK” 토큰으로 치환하여 학습을 진행했다.
세부 학습 방식
- LSTM의 파라미터들을 -0.08~0.08 사이의 값을 갖는 균일 분포로 초기화했다.
- 파라미터 최적화를 위해 momentum 없이 SGD(Stochastic Gradient Descent)를 사용했다.
- 초기 5 epoch동안 학습률을 0.7로 고정하였고, 이후 0.5 epoch마다 학습률을 절반으로 낮추면서 7.5 epoch까지 학습시켰다.
- gradient를 구하기 위해 배치 사이즈를 128로 설정하였고, 그렇게 구해진 gradient를 128로 나누어 사용하였다.
- LSTM은 vanishing gradient 문제에는 비교적 자유로운 대신, exploding gradient 문제가 발생할 수 있다. 따라서 exploding gradient 문제를 방지하기 위해 gradient의 norm이 일정 값 이상일 경우 gradient 값을 재조정하여 제한을 두었다.
- mini batch에서 문장 간에 길이 차이가 나는 경우 연산을 위해 문장의 길이를 맞춰줘야 하는데, 길이 차이가 많이 나게 되면 문장 길이를 맞추기 위해 들어가는 padding이 너무 많아지게 되고, 이는 무의미한 연산 작업을 야기하기 때문에 비효율적이다. 따라서 mini batch에 존재하는 문장들 간에 길이를 최대한 맞춰주었다.
- 연산 속도를 증가시키기 위해 다중 GPU를 사용해 모델 병렬화를 사용하였다.
평가 방식
기계 번역된 문장의 품질을 평가하기 위해 사용되는 BLEU score를 평가 지표로 사용했다.
결과
baseline 모델인 SMT(Statistical Machine Translation)의 경우, 33.3점의 BLEU 점수를 얻었다.
LSTM이 단독으로 사용된 경우, 앙상블 기법을 적용한 5개의 LSTM 모델에 입력 문장의 순서를 뒤집어 전달하고, decoder의 beam size가 12인 모델이 가장 높은 점수인 34.81점을 받았다.
위 결과에서 앙상블 기법으로 5개의 모델을 사용했을 때 beam size를 상대적으로 작은 숫자인 2개로 설정했음에도 beam size가 12일때와 점수 차이가 크지 않다는 점을 살펴볼 수 있다.
SMT와 함께 사용된 경우에서는 입력 문장의 순서를 뒤집어 전달받는 LSTM을 5개 앙상블한 모델로 SMT가 생성한 1000개 문장의 점수를 다시 매겨 출력 문장을 선택하는 모델이 가장 높은 점수인 36.5점을 받았다.
분석
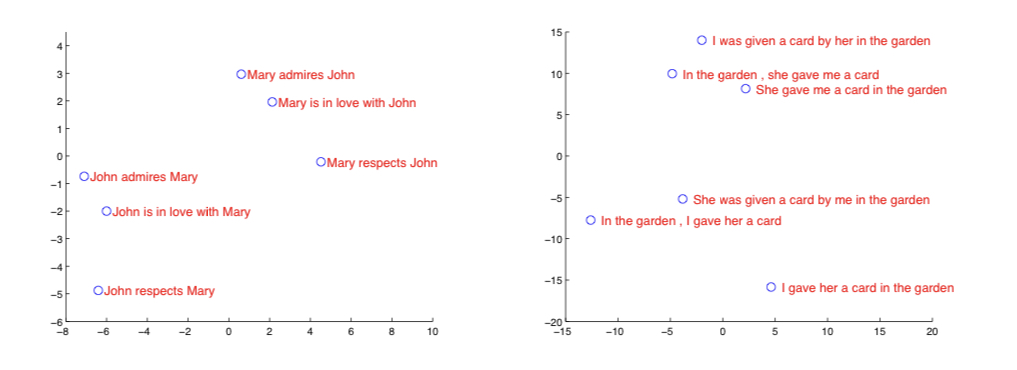
위 표는 입력 sequence를 처리하여 얻은 hidden state(즉, 문맥 벡터 v)를 2차원으로 PCA한 결과이다.
비슷한 의미끼리 군집을 이루고 있는 것을 확인할 수 있고, 어순이 바뀌었을때 의미를 다르게 해석한다는 것을 알 수 있다. 이 부분에서 bag-of-words보다 발전된 성능을 갖는 모델임을 알 수 있다.
또한, I was given a card by her in the garden과 In the garden, she gave me a card 두 문장이 같은 군집에 속해 있는 것을 통해 능동태에서 수동태로 변하면서 어순은 바뀌지만, 뜻이 바뀌지 않는 문장도 적절히 처리하고 있음을 알 수 있다.
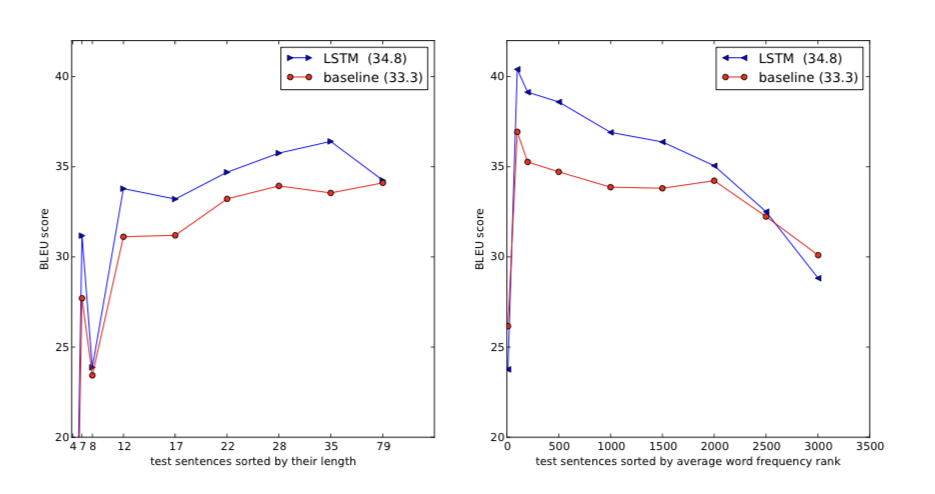
왼쪽 표를 살펴보면 입력 문장의 길이가 길어지더라도 long term dependency를 잘 유지하여 좋은 품질의 출력 문장을 생성해 낸다는 것을 알 수 있다.
오른쪽 표는 문장에 속한 단어들이 자주 등장하지 않는 어휘일수록 번역의 품질이 떨어진다는 것을 확인할 수 있다.
참고
https://arxiv.org/abs/1409.3215 (논문)
https://blog.naver.com/PostView.naver?blogId=sooftware&logNo=221809101199 (beam search)
*본 템플릿은 DSBA 연구실 이유경 박사과정의 템플릿을 토대로 하고 있습니다.