프로젝트 개요

Open-Domain Question Answering은 지문이 주어지지 않은 상황에서 사전에 구축된 knowledge resource를 기반으로 질문에 맞는 적절한 문서를 찾아 답변하는 task이다. 일반적으로 질문에 적절한 문서를 찾아주는 retriever와 문서를 읽고 적절한 답변을 찾거나 생성하는 reader의 조합으로 task를 해결한다.
- input: 질문 문장
- output: 질문에 알맞은 답변 문장
- 평가 지표
- Exact Match: 모델의 예측과 실제 답이 정확히 일치하는지 평가
- F1 Score: 모델의 예측과 실제 답이 결치는 단어가 존재하면 부분 점수를 주는 방식으로 평가
GitHub 협업
PR / Issue 템플릿 배포
팀 GitHub 협업 규칙에 따라 이번 프로젝트에서는 PR과 Issue 메세지를 작성할 일이 많아졌기 때문에, PR과 Issue 메세지를 작성할 때 반복적으로 작성해야 하는 내용들을 템플릿으로 만들어 배포했다. 이를 통해 팀원들에게 메세지 작성 가이드라인을 제공함과 동시에 메세지 작성 시간을 절약할 수 있었다.
Commit Convention 제정
commit 메세지의 header, body, footer에 어떤 내용을 작성할지 팀 commit convention을 정했다. header는 prefix와 함께 전체적인 작업 내용을 설명하는 문장을 적고, body에는 세부적인 구현 사항을 적기로 했다. 마지막으로 footer는 해당 commit과 관련된 issue의 번호를 적어, commit과 issue를 연결했다. 이렇게 팀 commit convention을 정함으로써 commit 메세지를 통해 작업 내용을 한눈에 확인할 수 있게 되었다.
CI 파이프라인 구축
프로젝트 기간동안 여러 팀원들이 master 브랜치로 코드를 merge하면서, 코드가 수시로 바뀌게 된다. 이 때마다 코드의 무결성을 확인하기도 어렵고, 시간도 많이 들기 때문에 자동으로 master 브랜치의 코드를 테스트하기 위한 CI 파이프라인을 구축했다. 내가 CI 파이프라인을 구축한 과정들은 아래 링크에서 확인할 수 있다.
GitHub Actions를 활용한 CI 구축
Open Domain Question Answering 프로젝트를 진행하면서 코드를 수정하여 merge할 때마다 해당 코드에 문제가 없는지 테스트를 진행해야 할 필요성을 느꼈다. train과 inference가 평균적으로 1시간 가까이 걸
sangwonyoon.tistory.com
master 브랜치에 코드를 직접 push하거나 PR을 할 경우, 코드에 대한 테스트가 자동적으로 수행되기 때문에, 매번 테스트해야하는 번거로움을 줄이고, 시간을 절약할 수 있었다.
베이스라인 코드 Refactoring
CSV 형식의 데이터를 읽을 수 있도록 수정
pyarrow 형식의 데이터만을 읽을 수 있었던 기존 베이스라인 코드를 CSV 형식의 테이터를 읽어 학습 및 추론 과정에 사용할 수 있도록 리팩토링 하였다. 이를 통해, 데이터의 분석과 증강이 용이해졌다.
Generation based MRC
Generation based MRC를 도입하게 된 동기
기존 reader 모델은 본문에서 정답을 추출해 내는 extraction based MRC 방식을 사용했다. 이 프로젝트에서 사용하는 데이터 셋은 본문 내에 반드시 정답이 존재하기 때문에 문제가 되지 않지만, 본문 내에 정답 내용이 온전하게 존재하지 않는 경우, 즉, 정답을 추출할 수 없는 경우에는 extraction based MRC로는 정답을 맞출 수 없다. 따라서 일반적인 상황에서 활용할 수 있는 generation based MRC 방식의 reader 모델을 개발하는데 집중했다.
학습 및 추론 코드 구현
generation based MRC를 개발하기 위해 encoder-decoder 구조의 T5 모델을 사용했다. T5 모델을 학습시키기 위해 기존 베이스라인의 학습 코드에서 모델에 주어지는 입력 값, 모델이 예측한 결과 값을 후처리하는 함수, 평가 지표 계산 방식을 수정하여 huggingface trainer를 활용한 학습 코드를 구현했다. 추론 코드의 경우, retrieval 모델이 찾아낸 질문과 연관성이 높은 k개의 본문을 가지고 데이터 셋을 만든 뒤, data loader를 통해 데이터를 모델에 입력하여 예측 값을 생성했다.
모델이 예측한 정답 후보 중 정답을 선택하기 위한 Score 함수 구현
retrieval 모델이 검색한 k개의 본문와 질문을 tokenizing하여 모델에 입력하면 하나의 질문에 대해 여러 데이터 셋이 모델의 입력으로 주어지게 된다. 따라서 모델은 하나의 질문에 대해 여러 개의 정답을 예측 값으로 내놓게 된다. 이 때, 모델이 예측한 여러 개의 정답 중 가장 높은 confidence로 예측한 하나의 정답만을 해당 질문의 정답으로 사용해야 하기 때문에, 각 예측 값에 대한 모델의 confidence score를 계산하는 함수를 구현했다. 하나의 예측 값에 대해 모델이 생성한 각 토큰의 probability의 logit 값을 모두 더하면 해당 예측 값에 대한 누적 probability의 logit 값을 계산할 수 있다. 그러나, 앞에서 설명한 계산 방식은 길이가 긴 seqeunce의 경우, probability가 낮게 계산되기 때문에 length penalty를 도입해 길이가 긴 sequence의 probability 값을 보정했다. length penalty는 beam search에서 probability를 계산할 때 적용하는 length penalty 공식을 적용했다.
def length_penalty(length, alpha=1.2, min_length=5):
return ((min_length + length) / (min_length + 1)) ** alpha
def compute_cumulative_prob(sequence, score):
total_prob = 0
len = 0
for seq, sc in zip(sequence[1:], score):
if seq == 1:
break
len += 1
# total_prob *= np.exp(sc.cpu().numpy())
total_prob += sc.cpu().numpy()
return np.exp(total_prob / length_penalty(len))기타 사항
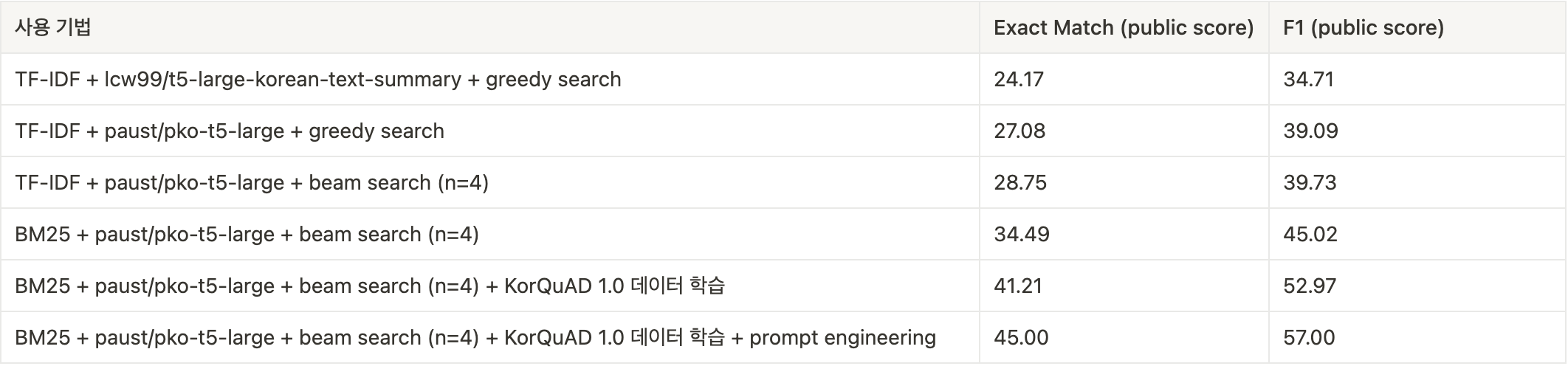
- beam search를 적용하여 성능을 향상시켰다.
- KorQuAD 1.0 데이터 셋을 모델에 추가로 fine-tuning 시켜 성능을 향상시켰다.
Prompt Engineering
질문과 본문 내용 구분
generation based MRC에서 사용한 모델인 paust/pko-t5-large는 extraction based MRC에서 사용하는 모델인 klue/roberta-large와 달리, tokenizer에 2개의 문장을 넣었을 때, 두 문장을 [SEP] 토큰으로 분리해주지 않기 때문에, 모델이 질문 내용과 본문 내용의 구분이 어려울 것이라고 판단했다. 이를 위해 새로운 special token을 tokenizer에 추가하는 방법보다는, 사전 학습 과정에서 학습했던 토큰을 사용하는 것이 성능이 더 좋다는 인사이트를 지난 문장 내 개체 간 관계 추출 프로젝트에서 얻었기 때문에, 질문:과 본문: 토큰으로 질문 내용과 본문 내용을 구분해 주었다. 그 결과 prompt engineering을 적용한 이후, Exact Match 평가 지표 기준 약 4점이 향상되었다.
TAPT(Task-Adaptive PreTraining)
klue/roberta-large 모델에 TAPT 적용
MRC 형식의 데이터 셋에 대한 모델의 이해도를 높이기 위해 프로젝트에서 제공된 train 데이터 셋, validation 데이터 셋 뿐만 아니라, 외부 데이터 셋인 korquad v1 데이터 셋, korquad v2 데이터 셋을 합쳐 Masked Language Modeling 방식으로 모델에 학습시켰다. 15%의 확률로 랜덤한 토큰을 마스킹했고, learning rate는 klue/roberta-large가 사전 학습에서 사용했던 learning rate의 1/10인 1e-6을 적용하여 1 epoch동안 학습을 수행했다. TAPT를 적용한 모델로 fine-tuning을 거친 뒤, inference를 수행한 결과 TAPT를 적용하지 않은 모델에 비해 좋은 성능을 보이지 못해 최종 결과에는 반영되지 못했다.
모델 성능 결과
지난 대회에 비해 나아진 점
협업 측면
- 실험 내용을 GitHub Issue로 등록해서 commit을 issue와 연결할 수 있었다. 그로 인해, 다른 팀원의 작업 내용과 해당 작업에서 코드가 어떻게 바뀌었는지 손쉽게 확인할 수 있었다.
- 지난 대회에서는 대부분의 PR을 내가 생성해서 master 브랜치에 merge했지만, 이번 대회부터는 PR 템플릿을 도입하고, 팀원들이 본인의 코드는 본인이 PR을 보냄으로써 효율적으로 협업할 수 있었다.
실험 진행 측면
- 이번 대회에서는 평가 지표와 데이터, 모델을 충분히 이해하고 프로젝트를 진행하려고 노력했다. 또한, 현 시점에서 모델의 성능을 떨어뜨리는 문제가 무엇인지 정의하기 위해 모델의 validation 데이터 셋에 대한 예측 값과 정답 값을 비교하며 다음으로 진행할 실험의 방향을 잡았다.
코드 분석 측면
- 첫 프로젝트였던 문장 간 유사도 측정 프로젝트에서 huggingface trainer를 사용했을 때는 공식 문서와 구글링을 통해 추상적으로 코드를 이해하고 넘어갔지만, 이번 대회에서는 라이브러리의 소스 코드를 직접 분석하여 공식 문서와 구글링만으로는 완벽하게 이해되지 않았던 코드 동작 방식을 더 구체적으로 이해할 수 있었다.
보완할 점
실험 진행 측면
MRC task에서 텍스트 생성 모델과 관련된 연구 논문을 조사해보지 못했다. 다음 프로젝트에서는 논문을 적극적으로 탐색하여 관련 선행 연구에 대한 깊은 이해를 바탕으로 실험을 진행해 볼 것이다.
'프로젝트 회고' 카테고리의 다른 글
| 법률 조언 웹 서비스 LawBot 프로젝트 회고 (1) | 2023.08.01 |
|---|---|
| 개체 간 관계 추출(Relation Extraction) 대회 회고 (0) | 2023.05.21 |
| 문장 간 유사도 측정(STS) 대회 회고 (4) | 2023.04.23 |