대회 개요

관계 추출 (Relation Extraction) task는 문장 내의 Subject와 Object로 표시된 두 객체간의 관계를 예측하는 task이다.
sentence: 오라클(구 썬 마이크로시스템즈)에서 제공하는 자바 가상 머신 말고도 각 운영 체제
개발사가 제공하는 자바 가상 머신 및 오픈소스로 개발된 구형 버전의 온전한 자바 VM도 있으며,
GNU의 GCJ나 아파치 소프트웨어 재단(ASF: Apache Software Foundation)의 하모니(Harmony)와
같은 아직은 완전하지 않지만 지속적인 오픈 소스 자바 가상 머신도 존재한다.
subject_entity: 썬 마이크로시스템즈
object_entity: 오라클
relation: 단체:별칭 (org:alternate_names)관계 추출은 지식 그래프 구축을 위한 핵심 구성 요소로, 구조화된 검색, 감정 분석, 질문 답변, 요약과 같은 NLP 응용 프로그램에서 활용된다.
입력은 문장과 Subject, Object에 대한 정보가 각각 주어진다. 출력은 문장과 단어에 대한 정보를 통해 모델이 예측한 Subject와 Object의 관계를 30개의 클래스 중 하나로 예측한 pred_label과 각 클래스에 대해 예측한 확률 probs가 된다.
평가 metric은 KLUE-RE evaluation metric과 동일하게 no_relation 클래스를 제외한 Micro F1 score와 모든 class에 대한 area under the precision-recall curve(AUPRC)를 사용한다.
협업 방식
GitHub
지난 대회에서 코드가 중앙에서 관리되지 않아서 다른 팀원의 실험을 본인의 브랜치로 가져와 적용해보기 어려웠다는 피드백을 반영하고자, 내가 팀원들의 코드를 main으로 병합해서 리팩토링하여 main 코드가 팀원들의 실험 내용을 반영하도록 했다.
Notion
지난 대회에서 실험 진행 상황을 GitHub Issues를 통해 공유했지만, notion이 시각적으로 알아보기 편하고, 세부 내용들을 정리하기에 적합하다고 판단해서 이번 대회에서는 notion을 통해 실험 진행 상황을 공유했다.
WandB
지난 대회에서는 WandB의 개인 프로젝트에 실험 내용들을 기록해서 다른 팀원의 실험 결과를 확인하기 어렵다는 피드백을 반영하여 WandB 팀을 구성하여 실험 결과를 팀원들과 함께 공유했다.
Code Management
이번 대회에서 내가 중점적으로 맡은 부분이다.
베이스라인 코드 리팩토링
대회에서 제공된 베이스라인 코드를 전체적으로 수정하는 작업을 진행했다.
먼저 HuggingFace Trainer로 모델을 학습시키는 코드를 Pytorch Lightning을 사용하여 모델을 학습시키도록 수정했다. 지난 대회에서 모델을 직접 커스터마이징하지 못했던 가장 큰 이유가 HuggingFace Trainer를 사용했기 때문이었고, 따라서 이번 대회에서는 모델링 작업을 진행하기 위해서 Pytorch Lightning을 적용했다. 이때, 코드에 대한 깊은 이해 없이 구현하여 의도치 않은 방식으로 코드가 동작하는 상황이 없게끔 Pytorch Lightning의 공식 문서와 소스 코드를 확인하며 구현했다.
기존 베이스라인 코드에 존재하던 버그들도 수정했다. 버그 중 하나를 예로 들자면 subject와 object를 파싱하는 부분에서 딕셔너리 형태의 값을 문자열로 읽어와 ‘,’와 ‘:’를 구분자로 하여 객체를 추출하는 코드가 있었다. 이 코드의 경우, 객체 안에 ‘,’ 또는 ‘:’가 포함되어 있으면, 의도치 않은 방식으로 문자열이 분리되어서 객체를 잘못된 값으로 읽어오는 경우가 존재했다. 따라서 이 부분을 eval 함수로 딕셔너리 형태의 문자열을 딕셔너리로 치환하여 key를 통해 객체의 값을 올바르게 가져왔다.
# 기존 베이스라인 코드
for i,j in zip(dataset['subject_entity'], dataset['object_entity']):
i = i[1:-1].split(',')[0].split(':')[1]
j = j[1:-1].split(',')[0].split(':')[1]
subject_entity.append(i)
object_entity.append(j)# 수정된 베이스라인 코드
for i,j in zip(dataset['subject_entity'], dataset['object_entity']):
sub_dict, obj_dict = eval(i), eval(j)
subject = sub_dict["word"]
object = obj_dict["word"]
subject_entity.append(subject)
object_entity.append(object)실험 진행 상황을 실시간으로 확인할 수 있도록 f1 score, loss, learning rate, confusion matrix와 같은 다양한 지표들을 로깅하도록 구현했으며, 실험이 끝난 이후에도 팀원들끼리 서로의 실험 결과를 비교할 수 있게 WandB와 연동하도록 구현했다.
지난 대회에서 실험 환경의 config를 hard coding으로 수정할 때의 번거로움과 human error를 경험했기 때문에 이번 대회에서는 argparse와 omegaconf 모듈을 활용해 하나의 yaml 파일로 전체 실험의 config를 제어할 수 있도록 구현했다. 또한, yaml 파일을 공유하는 것만으로도 간단하게 실험을 재현할 수 있고, 실험의 config를 기록으로 남길 수 있다는 장점도 얻을 수 있었다.
def config_parser():
"""argparse로 yaml 파일의 경로를 받아온 뒤, omegaconf로 해당 yaml 파일에 정의된 config 값을 읽어와서 반환하는 함수"""
parser = argparse.ArgumentParser()
parser.add_argument('--config', type = str, default = 'config/default.yaml')
args = parser.parse_args()
config = omegaconf.OmegaConf.load(args.config)
return config베이스라인 코드는 뼈대가 되는 코드로서, 다른 팀원들이 이 코드에서 확장하여 구현하기 쉽도록 베이스라인 코드를 구현했다. 그 예로, 토크나이저에 special token을 추가할 수 있도록 구성하고, 그에 따라 모델의 embedding layer의 입력 차원의 크기를 토크나이저의 크기에 맞게 resize하도록 구현하여 special token이 추가되더라도 모델이 에러 없이 동작할 수 있게 했다.
main 코드 관리
팀원 개개인이 실험한 내용들을 쌓아 올리기 위해서는 main 코드에 팀원들이 구현한 내용들이 잘 반영되어야 한다는 것을 지난 대회를 통해 깨달았기 때문에 이번 대회에서는 main 코드 관리를 신경 써서 진행했다.
팀원이 구현한 내용을 Pull Request하면 해당 내용을 검수하고, 다른 팀원들이 손쉽게 사용할 수 있도록 코드의 컨벤션을 따르도록 수정하거나, 함수에 주석을 달고, 비슷한 기능을 하는 함수와 클래스끼리 모듈화하는 등의 리팩토링을 진행했다.
Data Preprocessing
Entity Representation
An Improved Baseline for Sentence-level Relation Extraction 논문에서 제안한 Entity Representation 기법은 모델이 두 객체 간의 관계를 더 잘 추출할 수 있도록 모델의 입력으로 주어지는 문장에 Subject와 Object 객체에 대한 정보를 표현하는 방법이다.
해당 논문의 실험 결과를 살펴보면, 문장 부호와 객체의 유형을 문장에 추가한 Typed entity marker (punct)가 RoBERTa 모델에서 압도적으로 좋은 성능을 보였으며, BERT 모델에서도 Typed entity marker과 비슷한 성능을 보이는 것을 확인할 수 있다.
논문에서 제시된 모든 Entity Representation 기법을 우리 실험에 적용해 본 결과, 논문의 결과와 유사하게 Typed entity marker (punct)가 가장 좋은 성능을 보이는 것을 확인할 수 있었다.
위 결과에 대한 이유를 분석해 본 결과, 문장 부호가 아닌 special token으로 entity의 속성을 표시한 기법들은 모델이 사전 학습 과정에서 마주치지 못한 새로운 token이 추가되기 때문에 모델이 문장 내에서 해당 token을 역할을 이해하기 어려웠을 것이다. 반면, 문장 부호는 이미 사전 학습 과정에서 학습된 token이므로 문장 부호끼리 유사한 vector representation을 가졌을 것이고, 이를 통해 문장 부호가 객체를 표현하는 역할을 한다는 것을 이해하기 수월했을 것으로 생각된다.
Modeling
TAPT
Don't Stop Pretraining: Adapt Language Models to Domains and Tasks 논문에서 제안한 TAPT(Task Adaptive Pretraining)는 기존의 대량의 말뭉치로 사전 학습하여 일반화 성능을 끌어올린 사전 학습 모델에 task에 특화된 데이터만을 가지고 추가로 MLM(Masked Language Modeling)을 진행하는 것이라고 논문에서 정의하고 있다. 모델에 TAPT를 적용하면 해당 task에 등장하는 문장들에 대한 이해도가 높아진다는 것이 논문에서 주장하는 내용이다. 실제로 논문의 실험 결과를 살펴보면 RoBERTa에 TAPT를 적용한 결과 모든 task에서 성능이 향상된 것을 확인할 수 있었다.
따라서 우리 모델에도 train과 test 데이터 셋을 활용해 TAPT를 적용하면 성능이 향상될 것이라고 가설을 세우고 실험을 진행했다. KLUE 데이터 셋으로 사전 학습된 BERT와 RoBERTa 모델에 앞서 언급한 대로 대회에서 제공한 train과 test 데이터 셋을 바탕으로 Mask Language Modeling을 진행했다.
이후, ablation study를 위해 다른 조건들을 동일하게 고정한 뒤, TAPT를 적용한 모델과 적용하지 않은 모델의 성능을 비교해 보았다.
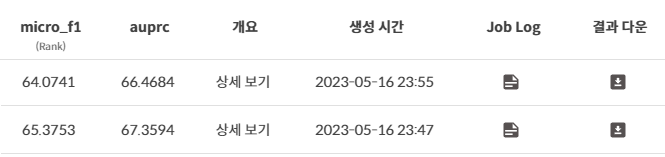
위 사진은 BERT 모델의 public score를 비교한 결과이다. TAPT 적용 이후 micro f1 score 기준 1.3점 가량 상승한 것을 확인할 수 있다.
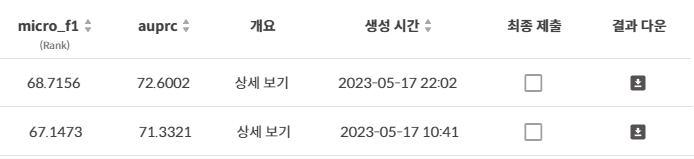
위 사진은 RoBERTa 모델의 public score를 비교한 결과이다. TAPT 적용 이후 micro f1 score 기준 1.6점 가량 상승한 것을 확인할 수 있다.
두 모델 중 성능이 더 잘 나온 TAPT를 적용한 RoBERTa 모델의 경우 다른 팀원들이 사용하기 쉽도록 HuggingFace Hub에 모델을 업로드했다.
최종 결과

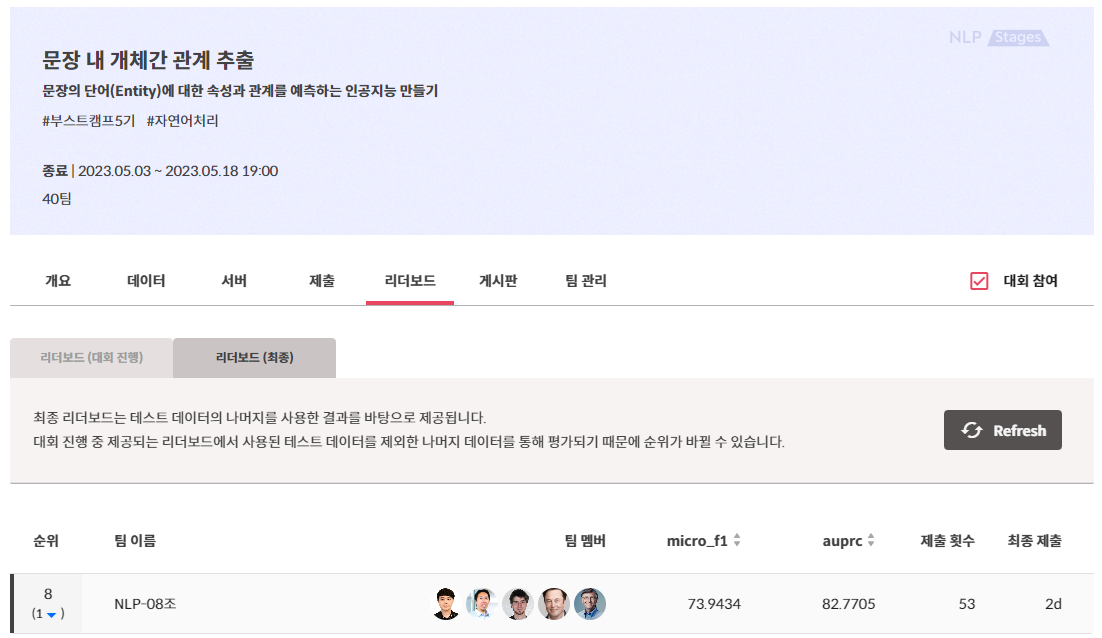
Public micro f1 score 75.5115점 7위, Private micro f1 score 73.9434점 8위로 마무리 지었다. 지난 대회에 비해 결과는 좋지 못하지만, 얻어가는 것은 더 많은 것 같다. 결과보다 과정이 더 중요하다고 생각하기 때문에 이번 대회가 지난 대회보다 더 뿌듯하다.
지난 대회에 비해 개선된 점
모델 측면
이번 대회에서는 Pytorch Lightning을 사용하면서, HuggingFace Trainer를 사용했던 이전 대회에 비해 쉽게 모델을 직접 수정하고, 다양한 learning rate scheduler, loss function, optimizer를 적용할 수 있었다. 이러한 경험을 통해 모델의 구조와 동작 방식에 대해 더 깊게 이해할 수 있었고, learning rate scheduler, loss function, optimizer가 모델에 미치는 영향을 더 직관적으로 살펴볼 수 있었다.
코드 관리 측면
main 코드 관리를 진행함으로써 팀원들 각자 구현한 코드를 공유하며 효율적으로 실험 진행될 수 있었다.
실험 진행 측면
지난 대회에서는 한 번의 실험에서 여러 기법을 동시에 적용하여 ablation study가 제대로 이뤄지지 못했는데, 이번 대회에서는 ablation study가 이뤄질 수 있도록 한 번의 실험에서는 하나의 조건만 조작하여 해당 조건이 모델의 성능에 미치는 영향을 파악할 수 있었다.
다음 대회에서 보완할 점
실험 진행 측면
이번 대회에서 코드 관리 파트를 담당하게 되어 대회 초반에는 데이터에 대한 분석이나 모델 관련된 실험을 진행하지 못했다. 그로 인해, 대회 막바지에 급하게 실험을 시도하다 보니 데이터와 평가 지표, 모델에 대한 분석을 깊게 하지 않고, 관계 추출 task에 적용할 수 있는 기법들을 마구잡이로 시도했던 것 같다. 다음 대회부터는 실험을 한두 개 덜 하더라도 평가 지표, 주어진 데이터와 현재 사용하는 모델들의 분석을 통해 현시점의 문제를 정의하고, 관련된 선행 연구를 조사하여 실험에 적용하는 방식으로 진행할 것이다.
'프로젝트 회고' 카테고리의 다른 글
| 법률 조언 웹 서비스 LawBot 프로젝트 회고 (1) | 2023.08.01 |
|---|---|
| Open-Domain Question Answering 프로젝트 회고 (0) | 2023.06.25 |
| 문장 간 유사도 측정(STS) 대회 회고 (4) | 2023.04.23 |