프로젝트 개요

법률 분쟁 상황에서 전문 분야 지식의 부재로 인한 정보의 격차를 해소하고, 누구나 평등하게 대처할 수 있도록 법률 조언을 해주는 챗봇 서비스이다.
서비스 이용자가 본인이 처한 법률적 상황을 설명하는 텍스트를 입력하면 LLM이 생성한 답변과 함께 유사한 상황의 판례에서 판례의 근거 조항들을 보여준다. 이를 바탕으로 사건이 법적 분쟁으로 이어질 때 고려해야 할 법령 조항들과 법률 조언을 확인할 수 있다.
개발 내용
아키텍처 구성
프로젝트 진행을 위해 네이버 커넥트 재단으로부터 제공받은 V100 서버 4대를 모두 활용하기 위해 처음 설계할 때부터 서비스 확장이 쉬운 마이크로 서비스 아키텍처를 고려했다. 또한 서비스 간의 상호 의존도를 낮춰 서버에 장애가 발생할 경우 전체 서비스가 중단되는 것을 방지하고자 했다.
웹 서버, 모델 서버를 독립적으로 분리하고 API를 통해 서로 통신하는 구조로 설계했다. 이를 통해 한 대의 V100 서버에 장애가 발생하더라도 나머지 서비스는 전혀 영향을 받지 않고 서비스를 제공할 수 있었다.
CI 파이프라인
소스 코드를 작성하거나 수정할 때마다 어플리케이션의 모든 기능이 정상적으로 동작하는지 확인하는 것은 불가능에 가까웠다. 그러나, 문제를 뒤늦게 발견할수록 시간적인 비용이 더 많이 들었기 때문에 테스트 자동화가 필요했다.
이를 위해 GitHub Actions를 활용하여 develop 브랜치로 PR이 발생할 때 사전에 구현한 pytest 기반의 단위 테스트가 실행되도록 CI 파이프라인을 구축했다. 이번 프로젝트가 LLM 모델을 활용하기 때문에 GitHub에서 제공하는 서버로 답변 생성 테스트를 진행하는 것에 한계가 있었기 때문에 V100 서버를 self-hosted runner로 등록하여 CI 파이프라인을 운영했다.
CI 파이프라인을 통해 매번 테스트를 진행해야 하는 번거로움을 해소하고, 사전에 코드상의 문제를 파악하여 효율적으로 프로젝트를 진행할 수 있었다.
[GitHub Actions] Self-Hosted Runner를 활용한 CI 파이프라인 구축
지난 프로젝트에서 CI 파이프라인을 구축한 방법 지난 Open Domain Question Answering 프로젝트를 진행하면서 CI 파이프라인을 구축하기 위해 GitHub에서 제공하는 서버(GitHub-hosted runner)에서 GitHub Actions를
sangwonyoon.tistory.com
로드 밸런싱 적용
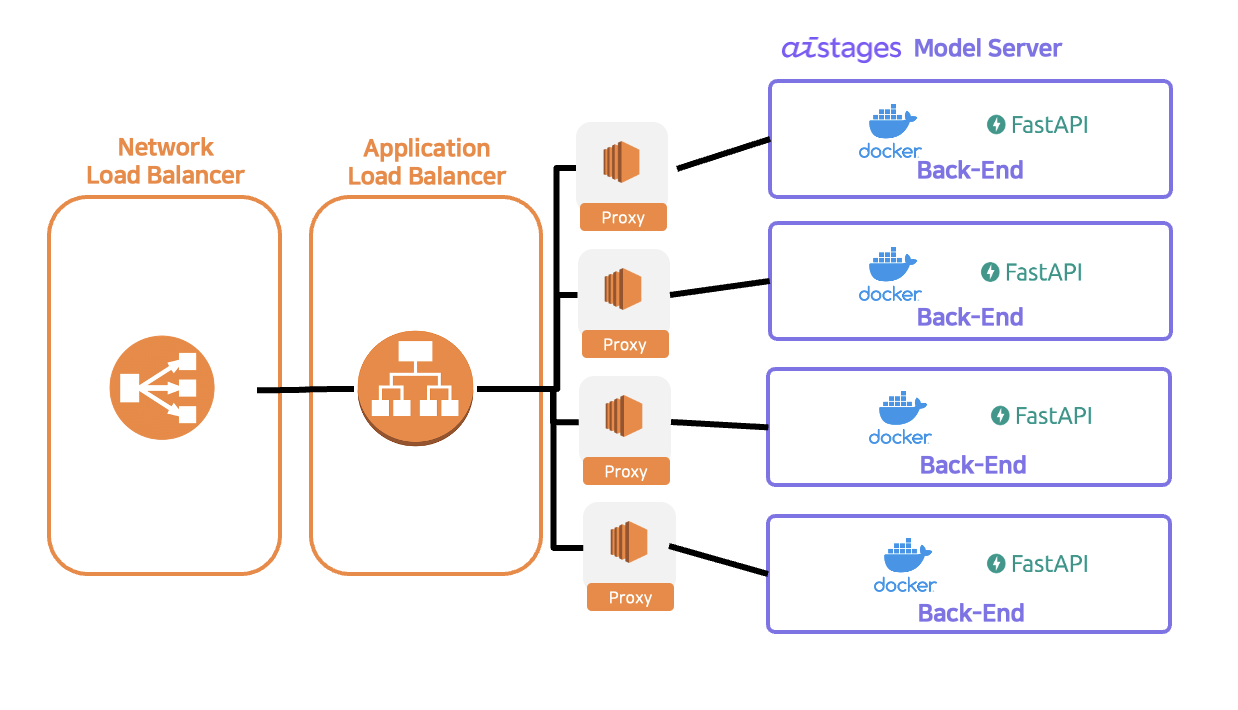
모델이 하나의 답변을 생성하고 유사 판례를 찾아오는 데 약 20초가 소요되기 때문에 다수의 이용자가 동시에 접속해 있는 경우, 한 대의 서버로는 트래픽을 감당하기 어려웠다.
트래픽을 4대의 V100 서버에 분산하기 위해 AWS의 Elastic Load Balancing을 사용했다. V100 서버 각각에 proxy 서버의 역할을 하는 EC2를 두고, Application Load Balancer를 4대의 proxy 서버와 연결하여 로드 밸런싱을 적용했다. 이때, Application Load Balancer는 고정 IP 주소를 지원하지 않기 때문에 Network Load Balancer를 Application Load Balancer의 앞 단에 배치하여 IP 주소를 고정했다.
로드 밸런싱을 통해 기존 1대의 모델 서버로 서비스를 운영했을 때보다 4배 많은 트래픽을 소화할 수 있었다. 또한 Applcation Load Balancer의 기본 기능 중 하나인 health check를 통해 모델 서버에 장애가 발생할 경우, 해당 서버로 트래픽을 보내지 않음으로써 서버의 장애가 서비스의 장애로 이어지는 것을 방지할 수 있었다.
AWS Elastic Load Balancing 적용하기
법률 조언 챗봇 프로젝트를 진행하기 위해 네이버 커넥트재단으로부터 제공받은 V100 서버 5대 중 4대를 모델 서버로 사용하고 1대를 CI 테스트 서버 및 모델 학습 서버로 사용하기로 계획했다. 따
sangwonyoon.tistory.com
Auto Scaling을 통한 고가용성 환경 구축
비용 절감을 위해 하드웨어 성능이 낮은 EC2 인스턴스를 사용하다보니, 종종 웹 서버가 트래픽을 감당하지 못해 장애가 발생했다.
이 문제를 해결하기 위해 웹 서버 그룹과 연결된 Application Load Balancer가 주기적인 health check로 서버의 장애를 빠르게 파악하고, Auto Scaling 기능을 통해 새로운 웹 서버를 장애가 발생한 웹 서버와 교체시켰다.
이로써 웹 서버의 장애를 빠르게 Failover하여 고가용성 환경에서 서비스가 유지될 수 있도록 했다.
모델 학습 파이프라인
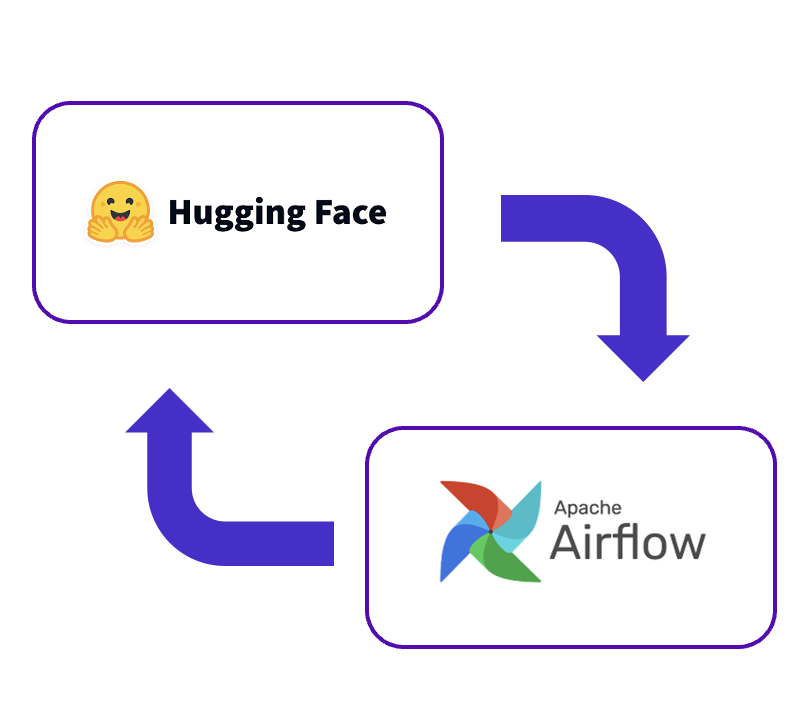
매주 새롭게 추가되는 법률 상담 사례들을 데이터셋에 추가하여 주기적으로 모델을 다시 학습시키기 위해 Airflow를 활용한 모델 학습 파이프라인을 구축했다. 일주일마다 HuggingFace 저장소에 올라온 새로운 데이터셋을 가져와 모델에 입력 가능한 형태로 전처리한 뒤, HuggingFace의 Trainer로 모델 학습을 진행한다. 학습이 끝난 모델은 모델 서버에서 사용 가능하도록 HuggingFace의 저장소에 업로드했다.
안전한 데이터 전달을 위한 HTTPS 통신 환경 구축
프로젝트의 특성상 서버에 전달되는 데이터가 사용자의 개인적인 정보가 포함되어 있을 수 있으므로, HTTPS 통신을 통해 안전하게 데이터가 전달되어야 했다.
이를 위해 도메인을 구입하여 해당 도메인에 대한 SSL 인증서를 발급받고, 이 인증서를 웹 서버와 연결된 Application Load Balancer에 등록함으로써 HTTPS 통신 환경을 구축할 수 있었다.
Route 53와 ACM을 사용해 도메인에 HTTPS 적용하기
법률 조언 챗봇 서비스의 접근성을 높이기 위해 도메인을 등록하고, 도메인에 HTTPS를 적용했다. 이번 포스팅에서는 AWS의 Route 53와 ACM 서비스를 활용해 진행한 과정을 공유해보려고 한다. 도메인
sangwonyoon.tistory.com
GPU 메모리와 latency의 trade-off를 고려한 구현
요청이 들어온 시점에 모델을 GPU 메모리에 로드하고 추론을 진행하게 되면 모델을 메모리에 로드하는 시간 때문에 추론 시간이 길어져 사용자 입장에서 서비스 만족도가 낮아지게 된다. 반대로 서비스에 사용되는 모든 종류의 모델(답변을 생성하는 LLM 외에도 법률 질문인지 확인하는 filtering 모델, 사용자의 질문과 유사한 QA 데이터가 있는지 검색하는 retrieval 모델, 유사 판례를 찾는 search 모델이 있다.)을 미리 메모리에 로드해놓기에는 서버의 GPU 메모리 크기의 한계가 있기 때문에 적절한 trade-off가 필요했다.
가장 효율적으로 메모리를 사용하기 위해 메모리에 로드되는데 소요되는 시간이 길고, 항상 메모리를 점유하고 있더라도 서비스 전체가 실행되는 동안 CUDA Out of Memory 에러가 발생하지 않도록 고려하여 LLM 모델과 retrieval 모델을 미리 로드해놓고, filtering 모델과 search 모델은 요청이 들어올 때마다 로드한 뒤, 메모리에서 해제하는 방식으로 구현했다.
이를 통해 latency를 적절히 줄이면서 서버에서 발생할 수 있는 CUDA Out of Memory 에러를 방지할 수 있었다.
GitHub flow 기반의 브랜치 전략
다양한 브랜치 전략 중 수시로 배포해야 하는 웹 어플리케이션에는 간단한 브랜치 구조를 갖는 GitHub flow가 가장 적합하다고 판단하여 채택했다.
GitHub flow의 브랜치 전략에서 develop 브랜치를 추가로 두어, 웹으로 배포하기 전 마지막으로 코드를 병합했을 때 발생할 수 있는 문제점을 테스트할 수 있도록 구조를 수정했다. 또한 개발 작업을 Issue 단위로 쪼개어 등록하고, 각 Issue에 해당하는 브랜치를 생성하여 작업하는 것을 원칙으로 했다. PR은 반드시 develop 브랜치로 보내야 하며, 코드 리뷰를 진행하여 최소 2명 이상의 팀원이 승인한 경우에만 develop 브랜치로 코드를 병합할 수 있도록 했다.
프로젝트를 진행하면서 느낀 점
실제 트래픽이 존재하는 서비스를 개발하면서 안정적으로 서비스를 제공할 수 있는 방법들에 대해 여러 고민을 할 수 있었던 귀중한 경험이었다. 또한, 반복적으로 수행되는 업무를 자동화함으로써 불필요한 시간과 노력의 낭비를 줄이고, 서비스 로직 구현에 집중할 수 있었다. 또한, AWS EC2 인스턴스 6대와 V100 인스턴스 5대를 모두 활용한 아키텍처를 구성하면서 여러 서버를 모니터링하고, 장애를 대처하는 경험을 할 수 있었다.
이번 프로젝트를 진행하면서 아쉬웠던 부분은 프로젝트 기간이 구현해야 하는 기능들에 비해 너무 짧았다보니 다른 팀원이 보기에도 이해하기 쉬운 코드를 작성하자는 내 개발 가치관을 지키지 못했던 것 같다. 사실상 백엔드 작업을 혼자 진행하다 보니 협업하는 팀원이 없어서 더 가독성을 고려하지 않고 코드를 짠 것 같은데, 처음부터 좋은 습관을 들이는 것이 중요하기 때문에 앞으로는 협업하지 않는 환경에서도 읽기 쉬운 코드로 작성하도록 노력해야 겠다. 프로젝트가 어느정도 마무리되면 함수를 설명하는 주석을 추가하고, 더 나은 가독성과 로직을 위한 리팩토링을 진행할 예정이다.
'프로젝트 회고' 카테고리의 다른 글
| Open-Domain Question Answering 프로젝트 회고 (0) | 2023.06.25 |
|---|---|
| 개체 간 관계 추출(Relation Extraction) 대회 회고 (0) | 2023.05.21 |
| 문장 간 유사도 측정(STS) 대회 회고 (4) | 2023.04.23 |