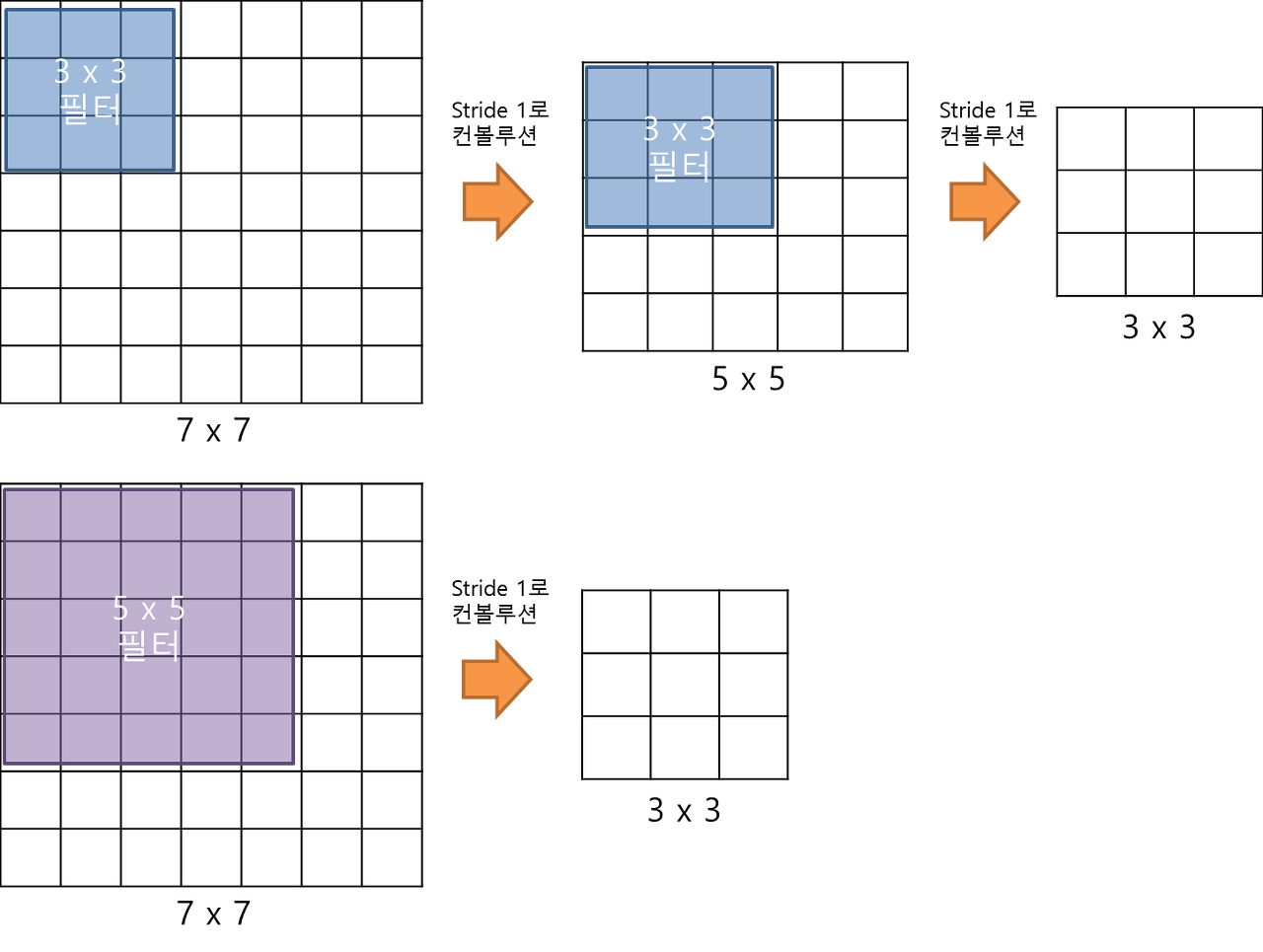
ILSVRC라는 Visual Recognition Challenge와 대회에서 수상을 했던 4개의 Network의 특징에 대해 알아보자. VGGNet convolution filter의 크기를 가장 작은 크기인 3x3으로 고정시켜 모델의 layer를 깊게 만들고, 파라미터의 수는 상대적으로 적게 줄였다. 3x3 filter로 두번 convolution 연산하는 것과 5x5 filter로 한번 convolution 연산하는 것은 같은 크기의 receptive field를 갖는다. 그러나, 3x3 filter를 2번 사용하는 것이 파라미터의 수가 훨씬 적게 필요하다. (3*3*2 < 5*5) 3x3 convolution filter를 사용함으로써 네트워크의 깊이가 깊어져 비선형성이 증가하고, 파라미터의 수는..