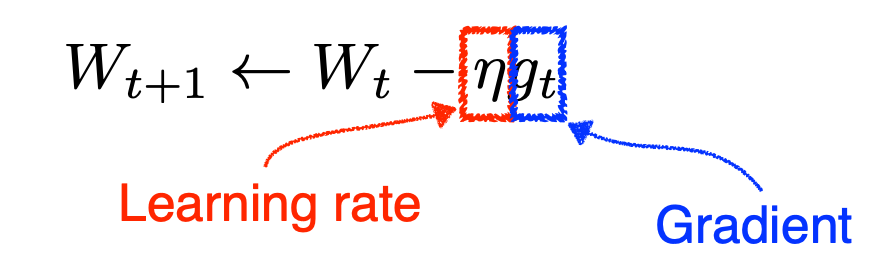
Gradient Descent 1차 미분 계수를 활용해 파라미터를 최적화한다. 문제점 적절한 Learning rate를 설정하는 것이 어렵다. global minimum이 아닌, local minimum로 수렴할 수 있다. Momentum 이전 gradient에 대한 정보를 활용하여 파라미터 값을 업데이트한다. 문제점 momentum으로 인해 loss function의 minimum 값에 수렴하지 못하고, 발산하는 문제가 발생한다. Nesterov Accelerated Gradient momentum과 비슷한 방식이지만, gradient 대신 Lookahead gradient를 활용한다. Lookahead gradient는 현재 시점의 gradient가 아닌, 다음 예상 위치의 gradient이다. Lo..