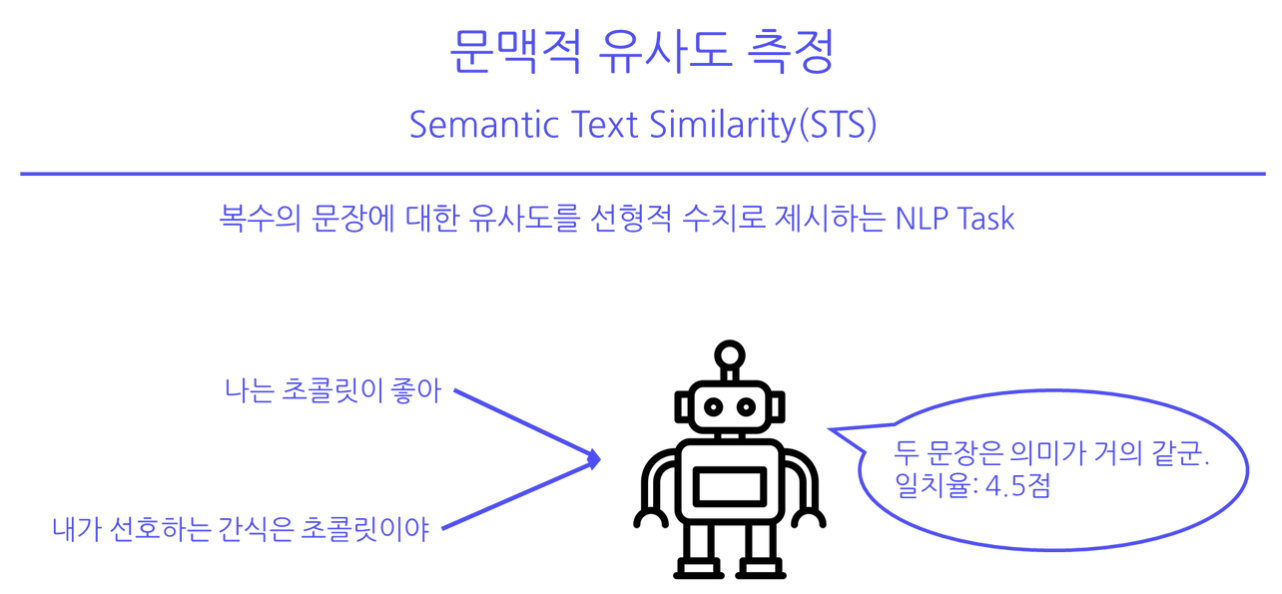
대회 개요 STS (Semantic Textual Similarity) task는 두 개의 문장이 주어졌을 때, 이 두 문장 사이의 의미적 유사도를 측정하는 자연어 처리(NLP) task이다. STS task는 NLP 분야에서 중요한 문제 중 하나로, 텍스트 매칭, 정보 검색, 자동 요약, 기계 번역 등의 응용 프로그램에서 유용하게 활용된다. STS task는 주로 평가를 위해 사용되며, 주어진 두 문장 사이의 유사도를 0부터 5까지의 점수로 평가하는 것이 일반적이다. 이때, 0은 전혀 유사하지 않음을 나타내고, 5는 매우 유사함을 나타낸다. 학습 데이터셋 9324개, 검증 데이터셋 550개를 활용해 1100개의 평가 데이터에 대한 예측을 진행한다. 데이터 셋에는 두 개의 문장과 ID, 유사도 점수가 담..